配置RAG策略
RAG(召回与生成)策略是一种先进的自然语言处理技术,它结合了召回(Retriever)和生成(Generator)两个模块来处理信息和生成回答。这种策略特别适用于需要从大量数据中找到相关信息并生成准确回答的场景,比如企业知识库和专业的问答机器人等。
实现一个严肃的RAG企业知识库的工作步骤
虽然RAG系统在业界已经被充分讨论并有很多案例,但是要实现一个符合客户需求并能够稳定提供准确信息的RAG仍然需要很多工作,特别是需要根据不同企业文档的特性采取不同的处理策略,真正做到“千文千面”。
- 数据收集与整理: 收集可以用于回答的文档,并进行必要的整理,包括删除冗余和不必要的噪音,保证数据的正确性和一致性。
- 数据分段向量化: 这一步骤需要将收集整理好的文档进行分段向量化,并保存到向量数据库中。这一步骤非常关键,它决定了所生成的向量的有效性和查询的准确性。对于不同的文档特性需要采取不同的分段和向量化策略,比如对于长表格,如果文档分段过小,会导致表格被从中截断,使得查询到的文档只包含部分有效信息,也就导致了回答的不完整性。
- 根据查询召回文档: 当用户提问时,系统需要根据用户提问的语义相近度从向量数据库中找到相关文档并返回。虽然返回的文档从向量的相关性上已经有保证,但是从用户问题的角度并不一定适合。如果简单的把所有返回的文档直接丢给大语言模型进行处理,反而可能会导致混淆和错误发生。所以在召回阶段也可以使用不同的策略来处理返回的文档,确保准确性和有效性。
- 大语言模型处理: 召回有效的文档信息后,煎蛋平台会把信息作为相关上下文提供给各个所需的节点,可以在相关节点中直接开启“查询资料库”选项,或者在提示词中使用系统变量{{sys.context}}进行引用。
煎蛋平台的RAG策略配置
在煎蛋平台,你可以根据不同的文档特性配置详细的不同的RAG策略,包括向量化阶段和召回阶段。 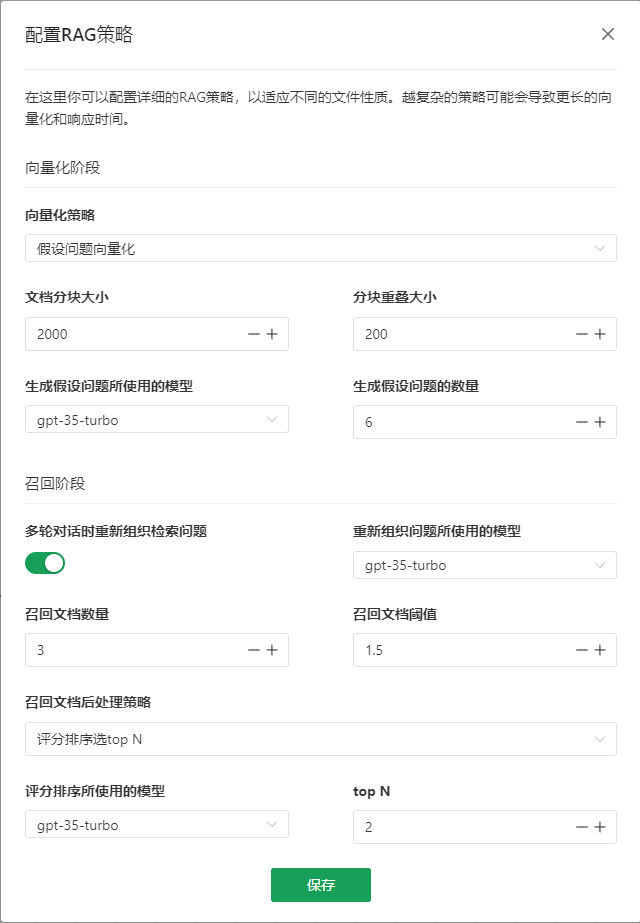
向量化阶段
你可以选择不同的向量化策略来适应不同的文档特性。更复杂的策略可能会产生更好的效果,但是也会导致响应速度变慢。在这一阶段如果使用的大语言模型处理,建议使用较小但是更快的模型,比如系统缺省使用的gpt 3.5 turbo模型。
注意: 修改向量化阶段的参数时,只会影响到未来新加的文档。对于已有文档,你可以选择是否重新进行向量化,还是保持原来生成的向量。通过保持原有文档的向量,并只对新文档应用新的向量化设置,你就可以实现不同的文档采用不同的向量策略的目的,真正实现“千文千面”。
原文分块向量化
这是简单的处理策略,把原文档分成特定大小的分块分别进行向量化。你可以选择不同的文档分块大小和分块间重叠部分的大小。
- 文档分块大小: 需要根据不同的文档特性选择合适的分块大小,比如问答对性质的文档可以选择较小的分段大小;对于包含长段表格和连续步骤的文档,需要选择更大的分段大小。
- 分块重叠大小: 因为无法保证每个分段都是切在合适的地方,所以可以额外配置分块间重叠部分的大小,这样在一个语义连续的文档被从中切断时,被切断的两个分段仍然有一部分信息可以关联,在向量化时更容易聚拢在一起。根据经验建议分块重叠大小设置为分块大小的10%,但是可以根据实际情况动态调整。
父子分块向量化
在处理包含长表格或者连续步骤的文档时,虽然可以通过设置较大的分块大小来包含更多的上下文信息,但是更大分块因为包含信息更多,在进行向量化时更不容易聚拢,导致后续用户进行查询时,往往返回的文档和用户原本问题的相关性不高。
在这种情况下可以采取父子分块向量化的策略,即将文档切成较大的分块(父分块),然后再进一步将父分块切分为较小的分块(子分块),然后将子分块进行向量化并保存到向量数据库中。在查询时,用户的问题更容易命中相关的子分块,然后通过子分块获取到父分块的原文档,并把原文档返回。这一策略既保证了信息的完整性,也保证了查询的相关性。
- 父文档分块大小:父分块的大小,根据文档特性设置为一个完整信息平均大小。
- 子文档分块大小: 子分块的大小。
分块总结向量化
和父子分块向量化策略类似,但是不是通过再细分子分块的方式,而是通过大语言模型的能力,自动对文档进行总结,然后把总结的信息向量化。这种策略的好处是从大分块中提取了关键信息,信息的准确性和相关性更高。
- 文档分块大小: 需要根据不同的文档特性选择合适的分块大小。
- 分块重叠大小: 分块间重叠部分的大小。
- 生成总结所使用的模型: 系统缺省使用gpt 3.5 turbo模型,也可以选择不同的模型来生成的总结信息。
假设问题向量化
和分块总结向量化的策略相似,但是不是生成文档总结,而是根据文档的内容生成不同的假设性问题,并把这些问题向量化。利用大模型根据内容从不同角度生成各种假设性问题,更容易在用户提到相似问题时命中。
- 文档分块大小: 需要根据不同的文档特性选择合适的分块大小。
- 分块重叠大小: 分块间重叠部分的大小。
- 生成假设问题所使用的模型: 系统缺省使用gpt 3.5 turbo模型,也可以选择不同的模型来生成的假设性问题。
- 生成假设问题的数量: 所生成的假设性问题的数量
召回阶段
多轮对话时重新组织检索问题
在多轮对话时,用户的最后一个问题可能并不完整,而用代词指代前文提到的对象,这个时候如果直接把用户问题的原文进行向量相似度查找,往往找到的文档不相关。
在这种情况下可以开启“多轮对话时重新组织检索问题”选项,通过大语言模型根据对话历史自动重新组织用户的问题,使得问题成为一个自洽包含完整信息的句子。在把新问题进行检索时返回的文档才会有更强的相关性。
- 重新组织问题所使用的模型: 系统缺省使用gpt 3.5 turbo模型,也可以选择不同的模型来重新组织问题。
召回文档数量
可以设置从向量数据中召回的文档数量,建议设置为2以上,这样即使关键信息被从中切断,仍然可以有机会合并成一个完整信息。
召回文档阈值
可以设置文档向量相似度的阈值。文档向量相似度值代表问题和文档在向量空间的距离关系,这个值越小代表相似度越高,信息相关性越高。相似度值大于这个阈值的文档将不会被返回。
召回文档后处理策略
这里可以设置从向量数据库召回文档之后是否需要进行更多额外处理。
- 全部选择: 对召回的文档不做额外处理,直接合并作为上下文提供给大语言模型。
- 评分排序选top N: 利用大语言模型的能力,对召回的文档从对用户问题的相关性进行评价打分,选取相关性最高的N个文档。
- 评分排序所使用的模型: 系统缺省使用gpt 3.5 turbo模型,也可以选择不同的模型来进行评价打分。
- top N: 选择顶部几个文档