Configuring RAG Strategy
RAG (Retrieve and Generate) strategy is an advanced natural language processing technique that combines the Retriever and Generator modules to handle information and generate responses. This strategy is particularly suitable for scenarios that require finding relevant information from large amounts of data and generating accurate answers, such as enterprise knowledge bases and professional Q&A bots.
Steps to Implement a Serious RAG Enterprise Knowledge Base
Although RAG systems have been extensively discussed in the industry with many cases, implementing a RAG that meets client needs and can consistently provide accurate information still requires a lot of work. It is especially important to adopt different processing strategies based on the characteristics of different enterprise documents, truly achieving the concept of "one size does not fit all."
- Data Collection and Organization: Gather documents that can be used to answer questions and organize them, including removing redundancy and unnecessary noise, ensuring the correctness and consistency of the data.
- Data Segmentation and Vectorization: This step involves segmenting the collected documents and vectorizing them, saving them in a vector database. This step is crucial as it determines the effectiveness of the generated vectors and the accuracy of the queries. Different segmentation and vectorization strategies should be adopted based on the characteristics of different documents. For example, with long tables, if the document segments are too small, the table may be truncated, leading to incomplete answers.
- Retrieve Relevant Documents Based on Queries: When a user asks a question, the system should retrieve relevant documents from the vector database based on semantic similarity. Although the returned documents are guaranteed to be relevant based on vector similarity, they may not necessarily be suitable from the user's perspective. If all the returned documents are directly passed to a large language model, it may lead to confusion and errors. Therefore, different strategies can be applied during the retrieval phase to process the returned documents, ensuring accuracy and effectiveness.
- Processing by the Large Language Model: After retrieving relevant document information, the Gendial platform provides the information as relevant context to the necessary nodes. The "Query Knowledge Base" option can be directly enabled in relevant nodes, or the system variable {{sys.context}} can be used to reference it in the prompt.
RAG Strategy Configuration on the Gendial Platform
On the Gendial platform, you can configure detailed RAG strategies based on the characteristics of different documents, including vectorization and retrieval stages. 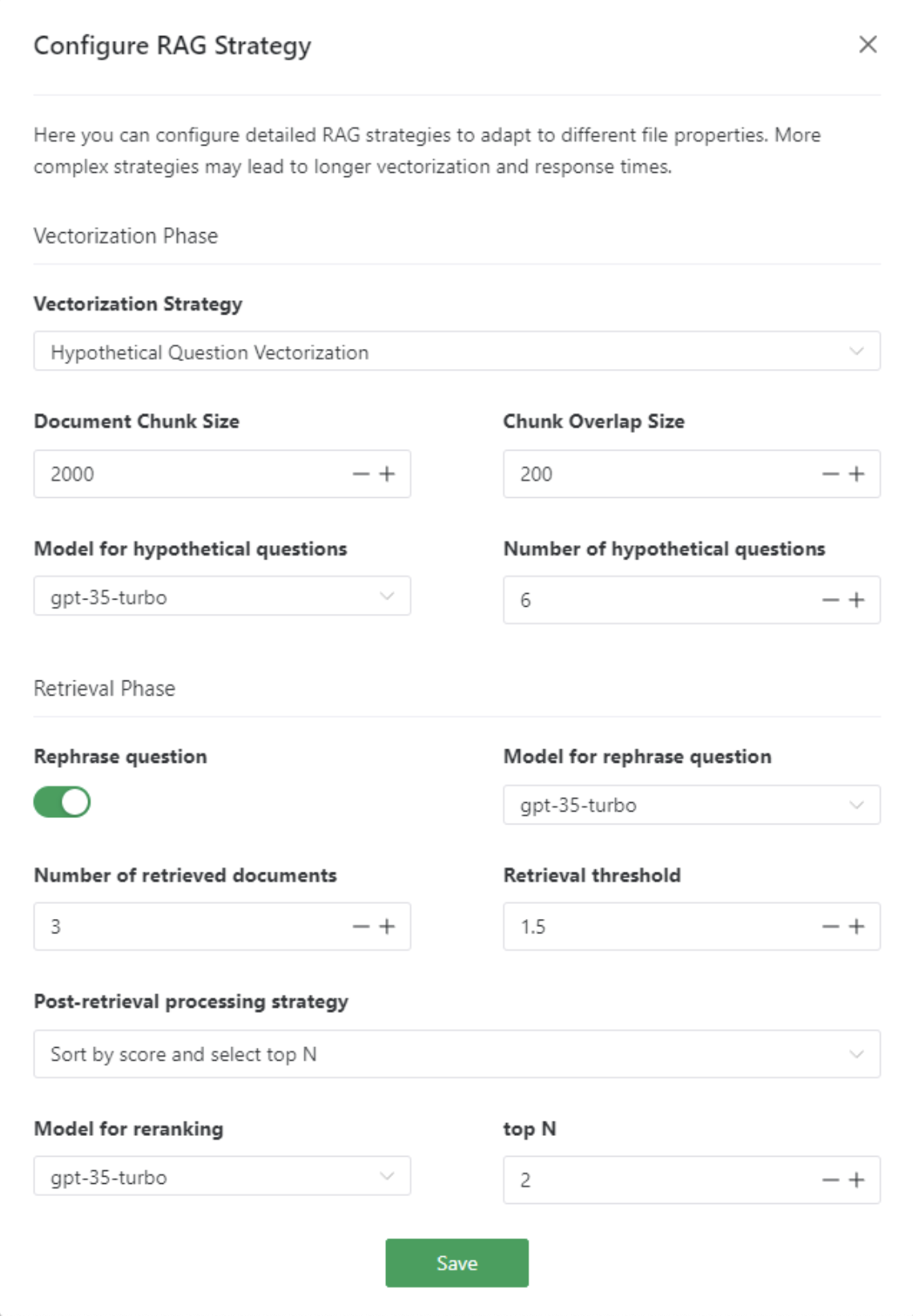
Vectorization Stage
You can choose different vectorization strategies to suit different document characteristics. More complex strategies may yield better results but may slow down response speed. When using a large language model for processing at this stage, it is recommended to use smaller but faster models, such as the default gpt-3.5 turbo model used by the system.
Note: Modifying parameters during the vectorization stage will only affect newly added documents. For existing documents, you can choose whether to re-vectorize them or keep the original vectors. By maintaining the vectors of the original documents and applying the new vectorization settings only to new documents, you can achieve different vectorization strategies for different documents, truly realizing the concept of "one size does not fit all."
Original Text Segmentation and Vectorization
This is a simple processing strategy that divides the original document into specific-sized chunks for vectorization. You can select the appropriate chunk size and the overlap size between chunks.
- Chunk Size: Choose an appropriate chunk size based on the characteristics of different documents. For example, for Q&A-type documents, smaller chunk sizes are preferable. For documents containing long tables or continuous steps, larger chunk sizes should be chosen.
- Chunk Overlap Size: Since it is not guaranteed that each segment is cut at an appropriate point, an overlap size can be configured. This allows chunks that have been split from a semantically continuous document to still share some common information, making it easier for the vectors to cluster together during vectorization. It is recommended to set the overlap size to 10% of the chunk size, though it can be adjusted dynamically based on the actual situation.
Parent-Child Chunk Vectorization
When processing documents containing long tables or continuous steps, although using a larger chunk size can include more context, larger chunks may be harder to cluster during vectorization, leading to lower relevance when querying.
In this case, a parent-child chunk vectorization strategy can be used. The document is first divided into larger chunks (parent chunks), which are then further split into smaller chunks (child chunks). These child chunks are vectorized and saved in the vector database. During querying, the user's question is more likely to match relevant child chunks, which will then retrieve the original parent chunk and return the original document. This strategy ensures both completeness of information and relevance during querying.
- Parent Document Chunk Size: The size of the parent chunk should be set based on the document's characteristics, typically to cover an average amount of information.
- Child Document Chunk Size: The size of the child chunk.
Summary Chunk Vectorization
Similar to the parent-child chunk vectorization strategy, but instead of subdividing child chunks, the document is automatically summarized by a large language model, and the summary information is then vectorized. The advantage of this strategy is that key information is extracted from large chunks, ensuring higher accuracy and relevance of the information.
- Chunk Size: Choose an appropriate chunk size based on the document's characteristics.
- Chunk Overlap Size: The overlap size between chunks.
- Model Used for Summarization: The default system uses the gpt-3.5 turbo model, but other models can also be selected to generate the summary information.
Hypothetical Question Vectorization
Similar to the summary chunk vectorization strategy, instead of generating a document summary, different hypothetical questions are generated based on the document's content, and these questions are vectorized. By leveraging a large model to generate various hypothetical questions from different angles, it becomes easier to match the user’s query when a similar question is raised.
- Chunk Size: Choose an appropriate chunk size based on the document's characteristics.
- Chunk Overlap Size: The overlap size between chunks.
- Model Used for Hypothetical Question Generation: The default system uses the gpt-3.5 turbo model, but other models can also be selected to generate hypothetical questions.
- Number of Hypothetical Questions Generated: The number of hypothetical questions generated.
Retrieval Stage
Reorganize Retrieval Questions in Multi-turn Conversations
In multi-turn conversations, the user’s last question may be incomplete and may refer to previous objects using pronouns. In such cases, if the original user query is directly used for vector similarity searching, the retrieved documents may be irrelevant.
In this case, the "Reorganize Retrieval Question in Multi-turn Conversations" option can be enabled. The large language model will automatically reorganize the user's question based on the conversation history, turning it into a self-consistent sentence with complete information. Only when the new question is searched will the returned documents be more relevant.
- Model Used to Reorganize the Question: The default system uses the gpt-3.5 turbo model, but other models can be selected to reorganize the question.
Number of Retrieved Documents
You can set the number of documents to be retrieved from the vector data. It is recommended to set this value to 2 or more, so that even if key information is truncated, there will still be an opportunity to merge it into a complete piece of information.
Document Retrieval Similarity Threshold
You can set the similarity threshold for document vectors. The document vector similarity value represents the distance relationship between the question and the document in vector space. A smaller value indicates higher similarity and higher information relevance. Documents with a similarity value greater than this threshold will not be returned.
Post-processing Strategy After Document Retrieval
Here you can set whether additional processing is needed after retrieving documents from the vector database.
- Select All: Do not perform additional processing on the retrieved documents; merge them directly and provide them as context to the large language model.
- Score and Sort Top N: Use the large language model to evaluate and score the retrieved documents based on their relevance to the user's question, selecting the top N most relevant documents.
- Model Used for Scoring and Sorting: The default system uses the gpt-3.5 turbo model, but other models can also be selected for evaluation and scoring.
- Top N: Select the top N documents.